

 服务器0元试用,首购低至0.9元/月起
服务器0元试用,首购低至0.9元/月起
NLP领域牛叉模型进展进行时:GPT-1→BERT→GPT-2→GPT-3 。
NLP领域牛叉模型进展进行时:GPT-1→BERT→GPT-2→GPT-3
GPT是Generative Pre-training Transformer的简称,是由Alec Radford编写的语言模型,2018年由埃隆·马斯克的人工智能研究实验室OpenAI发布。
1、2018年OpenAI提出GPT-1
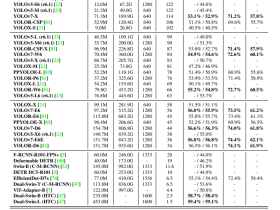
GPT 1.0采取预训练+FineTuning两个阶段,它采取Transformer的decoder作为特征抽取器,总共堆叠12个。预训练阶段采用“单向语言模型”作为训练任务,把语言知识编码到decoder里。第二阶段,在第一阶段训练好的模型基础上,通过Finetuning来做具体的NLP任务,迁移能力强。GPT系列其实是一个让人不能忽略的全程陪跑模型——OpenAI GPT(Generative Pre-Training)在以它的方式坚持着,向更通用的终极目标进发。
2、2018年10月谷歌推出的BERT
2018年10月推出的BERT一直有着划NLP时代的意义。
3、2019年2月OpenAI提出GPT-2
最初,埃隆·马斯克并不愿意发布它,因为他担心它可能被用来向社交网络发送假新闻。
GPT-2提出了meta-learning,把所有NLP任务的输入输出进行了整合,全部用文字来表示,比如对于翻译任务的输入是“英翻法:This is life”,输出是“C'est la vie”。直接把任务要做什么以自然语言的形式放到了输入中。通过这种方式进行了大规模的训练,并用了15亿参数的大模型,一举成为当时最强的生成模型,GPT-2 有着超大的规模,它是一个在海量数据集上训练的基于 transformer 的巨大模型。 GPT-2在文本生成上有着惊艳的表现,其生成的文本在上下文连贯性和情感表达上都超过了人们对目前阶段语言模型的预期。仅从模型架构而言,GPT-2 并没有特别新颖的架构,它和只带有解码器的 transformer 模型很像。
网友总结:GPT-2是对GPT的一个升级,并且更着重于将思路放在为何pretrain是有用的上面,认为LM本身是一个Multi-task Learner,并且大力用ZSL实验来佐证这个思路。GPT-2相比于GPT,笔者感觉主要有三点改进:大数据、大模型、insight观点。
但是,GPT-2在NLU领域仍并不如BERT,且随着19年其他大模型的推出占据了下风,年初微软推出的Turing-NLG已经到达了170亿参数,而GPT-2只有15亿。这些模型的尺寸已经远远超出了大部分公司的预算和调参侠们的想象。
4、2020年5月OpenAI提出GPT-3
Paper:GPT-3《 Language Models are Few-Shot Learners》的翻译与解读
2020年5月,OpenAI发布了GPT-3,这个模型包含的参数比GPT-2多了两个数量级(1750亿vs 15亿个参数),它比GPT-2有了极大的改进。根据论文描述,GPT-3非常强大,给予任何文本提示,GPT-3将返回一个文本完成,试图匹配用户给它的模式。用户可以给它 "编程",只需向它展示几个希望它做的例子,它就会提供一篇完整的文章或故事。GPT-3在许多NLP数据集上都取得了很强的性能,包括翻译、问题回答和cloze任务,以及一些需要即时推理或领域适应的任务,如在句子中使用一个新词或执行3位数运算。GPT-3可以生成人类评估人员难以区分的新闻文章样本。
的确,GPT-3看起来可以像人类一样理解、推理和对话的通用人工智能,但OpenAI警告说,他们可能遇到了根本性的扩展问题,GPT-3需要几千petaflop/s-day的计算量,相比之下,完整的GPT-2只有几十petaflop/s-day。
知乎评价:GPT-3依旧延续自己的单向语言模型训练方式,只不过这次把模型尺寸增大到了1750亿,并且使用45TB数据进行训练。同时,GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个缺点:
对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是很高的。
对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合训练数据分布,如果数据较少的话就可能造成过拟合,致使模型的泛华能力下降,更加无法应用到其他领域。
因此GPT-3的主要目标是用更少的领域数据、且不经过精调步骤去解决问题。
5、阶段性总结
最初的GPT只是一个12层单向的Transformer,通过预训练+精调的方式进行训练,BERT一出来就被比下去了。之后2019年初的GPT-2提出了meta-learning,把所有NLP任务的输入输出进行了整合,全部用文字来表示。
GPT-3的简介
Github:https://github.com/openai/gpt-3
GPT-3 是著名人工智能科研公司 OpenAI 开发的文字生成 (text generation) 技术,相关论文5月份已经发表,以天文数字级别的1750亿参数量引发学界轰动。
原文摘要:通过对大量文本语料库进行预训练,然后对特定任务进行微调,在许多NLP任务和基准上取得了实质性的进展。虽然在体系结构中通常与任务无关,但这种方法仍然需要成千上万个示例的特定于任务的微调数据集。相比之下,人类通常可以通过几个例子或简单的指令来执行一项新的语言任务——这是目前的NLP系统在很大程度上仍难以做到的。这里,我们展示了扩展语言模型可以极大地提高任务不可知的、小样本的性能,有时甚至可以通过预先采用的最先进的微调方法达到竞争力。具体来说,我们训练GPT-3,这是一个自回归语言模型,有1750亿个参数,比以往任何非稀疏语言模型多10倍,并测试其在小样本设置下的性能。对于所有任务,GPT-3的应用不需要任何梯度更新或微调,只需要通过与模型的文本交互指定任务和小样本演示。GPT-3在许多NLP数据集上实现了强大的性能,包括翻译、问题回答和完形填空任务,以及一些需要实时推理或领域适应的任务,如整理单词、在句子中使用新单词或执行3位数字算术。与此同时,我们也发现了一些数据集,其中GPT-3的小样本学习仍然存在困难,以及一些数据集,其中GPT-3面临着与大型网络语料库培训相关的方法论问题。最后,我们发现GPT-3可以生成人类评估者难以区分的新闻文章样本和人类撰写的文章样本。我们将讨论这一发现和GPT-3的更广泛的社会影响。
关于GPT-3 的影响
OpenAI 这次一反之前死守基础研究的思路,将 GPT-3 做成了一个服务,提供可以调用的 OpenAI API,并且向开放了少量体验资格,学术机构、商业公司和个人开发者都可以申请。
Latitude 透露,随着 GPT-3 的集成和新模式的推出,文字游戏内容的生成,和游戏系统对玩家输入文字所作出的反应,变得更加自然和连贯了,显著提高了玩家参与度,日活跃在2到2.5万人作用,也带动了高级版付费用户增长了大约25%。
关于GPT-3 的评价
程序员 Arram Sabeti 看来,GPT-3 最让他感到惊讶的不是写出来的内容有多“以假乱真”,而是它能够掌握几乎所有的文体和内容格式:从歌词到剧本,从产品说明书到新闻稿,从短篇故事到采访内容,似乎没有它搞不定的。
个人开发者 Kevin Lacker 做了一次图灵测试,发现 GPT-3 在绝大部分知识类、常识类、逻辑类的问题,甚至很多角度十分刁钻的问题上,表现非常令人惊讶。
关于GPT-3 的开源——为什么 OpenAI 决定发布 API,而不是开源整个模型?
1)将 GPT-3 技术商业化能够产生收入,继续支持 OpenAI 的人工智能科研、安全和政策研究方面的工作;
2)API 底层的模型其实非常庞大,开发和部署起来很复杂也很昂贵,据知情人士透露,训练一个模型就花了355个GPU年,耗资高达460万美元……所以除了大公司,其他人拿到模型也不会有任何收益。OpenAI 希望开放 API 能够让更多中小企业和机构获益;
3)把模型开放了,别人想怎么用怎么用,OpenAI 管不着。通过 API,OpenAI 可以控制人们使用这项技术的方式,对滥用行为及时治理。
GPT-3的安装
等待官宣,更新中……
GPT-3的使用方法
1、GPT-3的官方demo—原生能力,强到爆炸
(1)、Image GPT
https://www.openai.com/blog/image-gpt/
(2)、OpenAI 开发了一款浏览器搜索插件
这个插件就能根据你的问题,在当前网页找到答案,并将你指向对应的位置。

2、网友对GPT-3应用的二次开发
(1)、生成LaTeX 公式
Viaduct 公司机器学习工程师 Shreya Shankar 花了很长时间把玩 OpenAI 提供的 API,最终成功开发出了一个非常酷炫的 demo:英语 ➡️ LaTeX 翻译机!只需要用自然语言输入,就可以生成公式了!
(2)、Debuild 就能自动生成对应的 JSX 代码
文章末尾固定信息





评论